
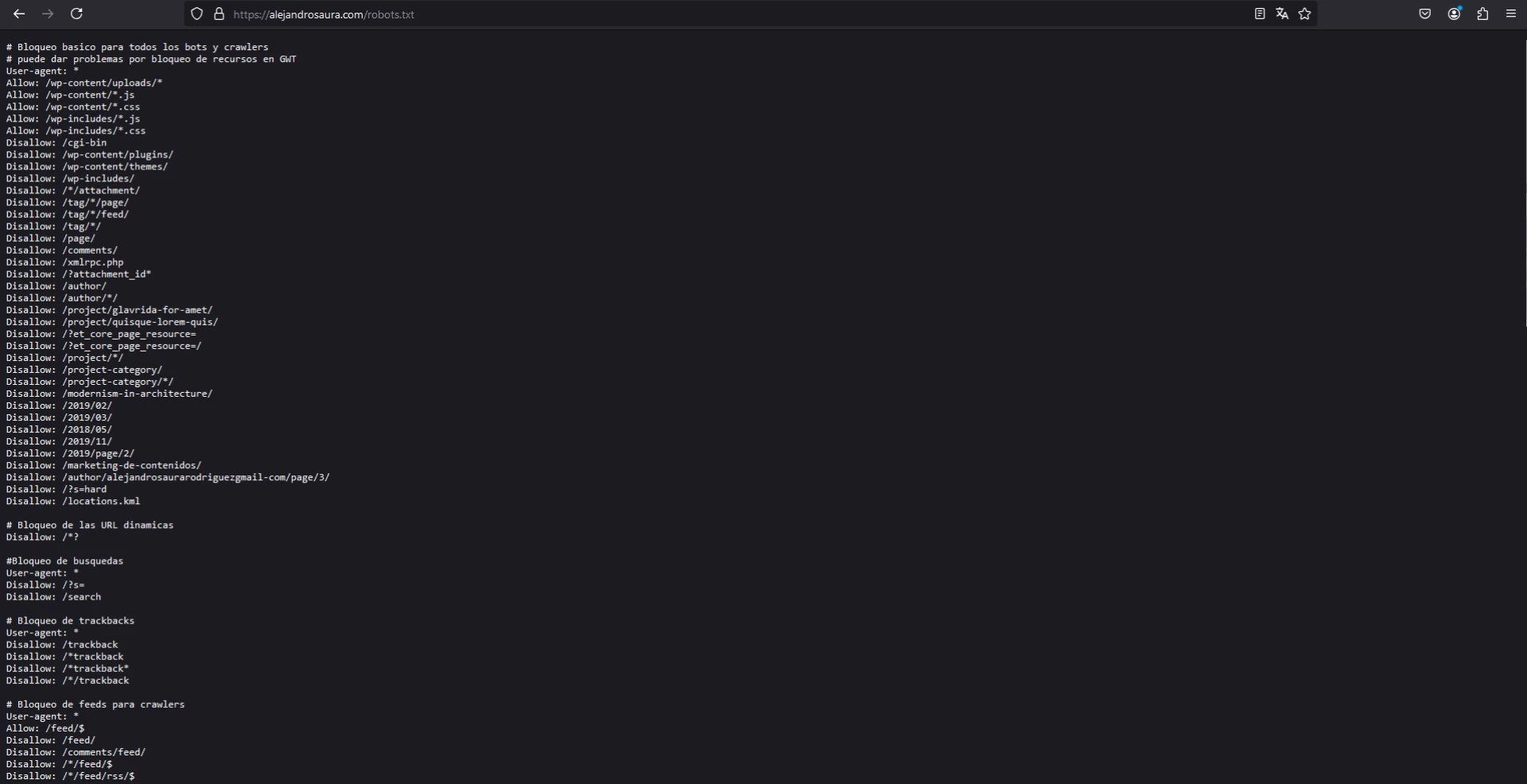
El archivo robots.txt es fundamental para la gestión del rastreo en un sitio web de WordPress. Este archivo indica a los motores de búsqueda qué partes del sitio pueden ser rastreadas y cuáles deben ignorarse.
Configurar correctamente el robots.txt puede mejorar significativamente el rendimiento SEO de tu sitio web. Además, es importante entender la diferencia entre el archivo robots.txt virtual que crea WordPress y una versión física editada por el usuario.

¿Qué es un archivo robots.txt en WordPress?
El archivo robots.txt es un componente esencial en la gestión del SEO de un sitio web. Su correcta comprensión y uso son claves para optimizar la interacción entre los motores de búsqueda y el contenido que se presenta en WordPress.
¿Para qué sirve el archivo robots.txt?
La principal función del archivo robots.txt es establecer directrices para los bots de los motores de búsqueda respecto a cómo deben rastrear el contenido de un sitio web. A través de este archivo, es posible indicar qué secciones pueden ser indexadas y cuáles deben ser ignoradas. Esto ayuda a manejar el tráfico de rastreo y a optimizar el rendimiento SEO.
El archivo actúa como una guía que permite a los motores de búsqueda entender la estructura y organización del contenido. Por ejemplo, al usar instrucciones específicas, tienes la posibilidad de evitar que se rastreen páginas que no aporten valor en términos de SEO, como páginas de agradecimiento o formularios internos.
Diferencia entre virtual y físico
En WordPress, hay una distinción entre el archivo robots.txt físico y el virtual. La plataforma genera automáticamente un archivo robots.txt virtual, que cumple funciones básicas de manera adecuada para la mayoría de los sitios. Sin embargo, este archivo no existe como tal dentro del sistema de archivos del servidor, lo que significa que no puede ser editado de manera convencional.
Por otro lado, un archivo robots.txt físico es aquel que se crea y sube al servidor por el usuario. Este archivo permite un mayor control y personalización de las directrices, ya que su contenido puede ser adaptado a las necesidades específicas de cada sitio.
Te recomiendo crear un archivo robots.txt físico en situaciones donde necesites configuraciones más complejas o cuando la estructura del sitio así lo demande.

Importancia del archivo robots.txt para el SEO
El archivo robots.txt desempeña un papel fundamental en la estrategia de SEO de un sitio web, ya que establece normas para los robots de búsqueda acerca de las páginas que deben ser rastreadas o ignoradas. Esta herramienta no solo influye en la indexación de contenido, sino que también puede mejorar la estructura general del sitio.
Relación con los motores de búsqueda
El archivo robots.txt establece directrices claras para los motores de búsqueda, facilitando el trabajo de rastreo y asegurando que los bots entiendan qué partes del sitio son accesibles. Esta relación es crucial, ya que una correcta configuración evita problemas de acceso y asegura que el contenido relevante sea priorizado en el proceso de indexación.
- Los motores de búsqueda utilizan el archivo robots.txt para determinar las áreas que deben explorar y las que deben evitar.
- Un archivo bien configurado puede aumentar la visibilidad de las páginas más importantes, dirigiendo el rastreo hacia el contenido que realmente merece ser indexado.
- Esto ayuda a optimizar el uso del presupuesto de rastreo, permitiendo a los bots concentrarse en las áreas que generan mayor impacto en el SEO.
Cómo afecta al rastreo de contenido
La configuración del archivo robots.txt tiene un impacto directo en cómo los motores de búsqueda rastrean el contenido del sitio. Una adecuada gestión de este archivo puede mejorar la eficiencia del rastreo y contribuir a una mejor indexación.
- Al especificar qué se debe y no se debe rastrear, se pueden evitar que los motores de búsqueda gasten recursos en páginas de bajo valor o que no aportan relevancia al contenido general del sitio.
- Esto permite que las páginas de mayor importancia tengan mayores oportunidades de ser indexadas, lo que a su vez puede influir positivamente en la clasificación en los resultados de búsqueda.
- Es vital tener en cuenta que el archivo robots.txt no previene la indexación, por lo que se deben complementar las directrices con etiquetas HTML como ‘noindex’ y ‘nofollow’ para un control más efectivo de la indexación de las páginas.

Cómo ubicar el archivo robots.txt en WordPress
Localizar el archivo robots.txt en un sitio de WordPress es un proceso sencillo, ya que existe una forma directa de acceder a él a través de la URL del sitio. También es fundamental entender las implicaciones del archivo por defecto que genera WordPress.
Acceso a través de la URL
Para encontrar el archivo robots.txt de un sitio web desarrollado en WordPress, es suficiente con introducir la URL del dominio seguida de ‘/robots.txt’. Por ejemplo, si el dominio es «tusitioweb.com», al acceder a ‘tusitioweb.com/robots.txt‘, se pueden visualizar las directrices que WordPress ha configurado automáticamente.
Este método de acceso permite consultar el archivo de manera rápida y sencilla, sin la necesidad de acceder a la parte administrativa del sitio. Sin embargo, es importante recordar que el contenido de este archivo puede variar según las configuraciones establecidas por el usuario.
Implicaciones del archivo por defecto
WordPress crea un archivo robots.txt virtual de manera automática, que aunque cumple con los requerimientos básicos de la mayoría de los sitios, puede no ser suficiente para todos los casos. Este archivo virtual contiene directrices que permiten a los bots de los motores de búsqueda interactuar con el contenido del sitio.
Una de las principales limitaciones del archivo por defecto es que no permite una personalización adecuada según las necesidades específicas del sitio. Por ejemplo, áreas como la carpeta /wp-admin/ están generalmente bloqueadas, lo que es positivo para la seguridad, pero en algunos contextos puede ser necesario permitir el acceso a ciertos archivos.
Es recomendable revisar el contenido del archivo por defecto y considerar modificarlo o crear uno nuevo que se ajuste mejor a los objetivos de SEO y a la estructura del sitio. Al hacerlo, se puede gestionar mejor el tráfico de rastreo y optimizar la indexación del contenido clave.
Cómo crear un archivo robots.txt para WordPress
Crear y editar un archivo robots.txt en WordPress puede ser necesario para ajustar cómo los motores de búsqueda rastrean el contenido de un sitio web. Existen varios métodos que permiten a los administradores modificar este archivo de manera eficaz.
Usando plugins de SEO
Los plugins de SEO son una de las formas más sencillas y eficientes para gestionar el archivo robots.txt en WordPress. Estas herramientas ofrecen interfaces amigables que simplifican el proceso de configuración, sin necesidad de conocimientos técnicos avanzados.
Creación con Yoast SEO
Yoast SEO es uno de los plugins más populares para optimizar el SEO en WordPress. Este plugin permite la creación y edición del archivo robots.txt de forma rápida y eficiente. Los pasos para utilizar Yoast SEO son:
- Acceder al panel de WordPress.
- Navegar a la sección de Plugins y buscar ‘Yoast SEO’ para instalarlo.
- Una vez instalado, activar el plugin desde el menú de administración.
- Ir a SEO, luego a Herramientas y seleccionar ‘Editor de Archivos’.
- Si no existe un archivo robots.txt, hay opción para crear uno nuevo.
- Editar el archivo según las preferencias del sitio y guardar los cambios realizados.
Creación con Rank Math
Rank Math es otra excelente opción para gestionar el archivo robots.txt en WordPress. Sigue estos sencillos pasos:
- Accede al panel de control de WordPress.
- Instala y activa el plugin Rank Math desde la sección de Plugins.
- Ve a «Rank Math» en el menú lateral y selecciona «Ajustes Generales».
- Busca y abre la sección «Editores de archivos».
- Edita el archivo robots.txt según las directrices que prefieras.
- Guarda los cambios y optimiza el rastreo de tu sitio por los motores de búsqueda.
A través de FTP
¡Mi opción preferida! Para aquellos que prefieren un enfoque más manual, se puede crear el archivo robots.txt directamente a través de FTP. Este método proporciona un control total sobre el contenido del archivo, pero requiere más conocimientos técnicos.
- Crear un archivo de texto plano en un editor como Notepad.
- Agregar las directrices necesarias en el archivo de texto.
- Guardar el archivo con el nombre ‘robots.txt’.
- Conectarse al servidor web usando un cliente FTP.
- Cargar el archivo ‘robots.txt’ en la carpeta raíz del sitio, comúnmente denominada ‘public_html’.
- Verificar que el archivo esté en minúsculas, ya que es sensible a mayúsculas y minúsculas.
Modificaciones desde Google Search Console
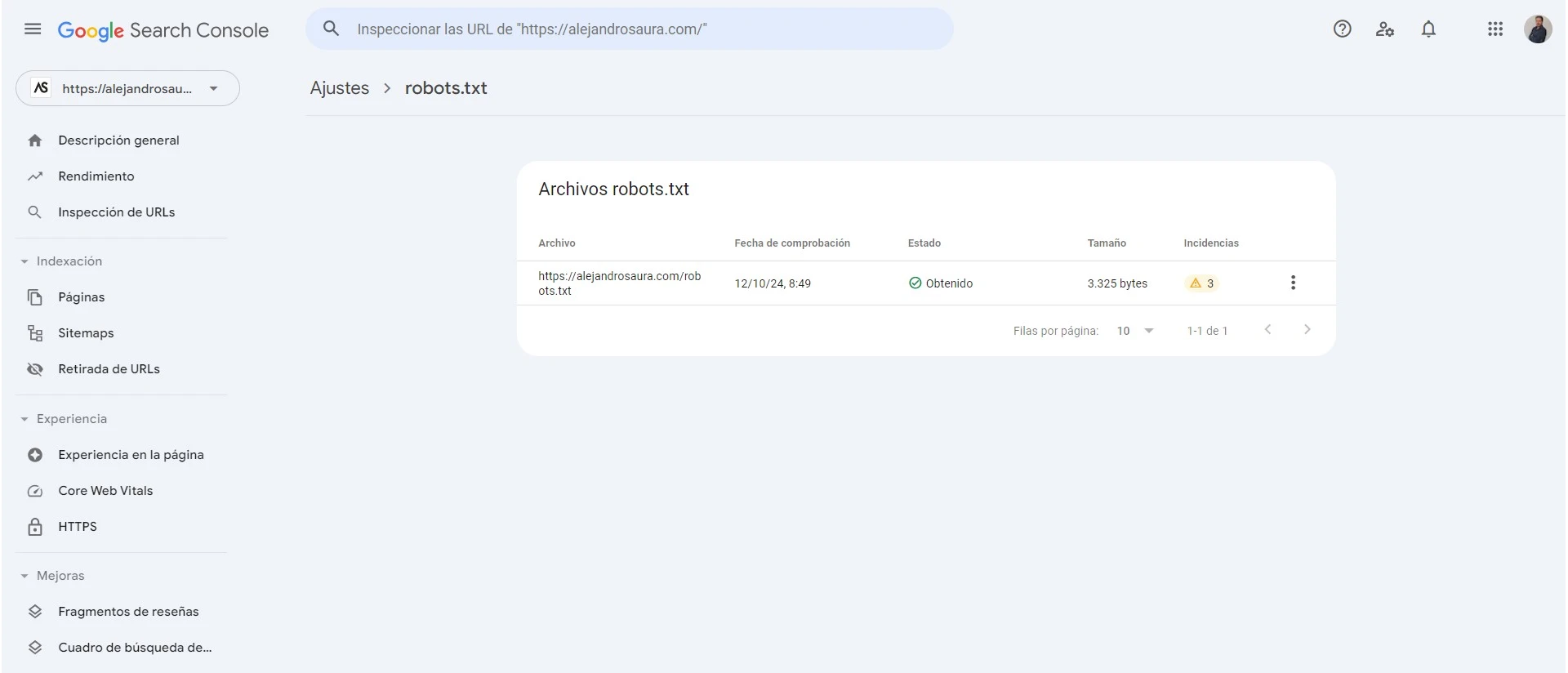
Google Search Console ofrece herramientas útiles para realizar modificaciones y comprobar el funcionamiento del archivo robots.txt. Aunque no permite editar el archivo directamente, se puede utilizar para validar que las directrices estén configuradas correctamente.
- Acceder a la cuenta de Google Search Console.
- Navegar a la sección ‘Rastreo’ y seleccionar ‘Probador de robots’.
- Introducir la URL del archivo robots.txt para comprobar su funcionamiento.
- Revisar posibles errores en la configuración y ajustar las reglas según sea necesario.
El archivo robots.txt permite definir directrices específicas para los bots de los motores de búsqueda. A continuación, se detallan las directrices más comunes que pueden incluirse en este archivo para optimizar su uso.
Directrices comunes en un archivo robots.txt
Uso de User-agent
La directiva User-agent es fundamental en la configuración del archivo robots.txt. Sirve para especificar a qué bot se aplican las reglas establecidas. Puede señalarse un bot en particular o utilizar un asterisco (*) para indicar que las reglas son aplicables a todos los bots.
Reglas de Disallow y Allow
Las directrices Disallow y Allow son esenciales para indicar qué partes del sitio web pueden ser rastreadas o deben ser ignoradas por los motores de búsqueda.
Cómo bloquear partes del sitio
Con la directiva Disallow, se puede restringir el acceso a ciertas áreas del sitio, algo clave para proteger contenido sensible o irrelevante para el SEO. Por ejemplo:
Disallow: /wp-admin/– Bloquea el acceso a la administración de WordPress.Disallow: /wp-includes/– Impide el rastreo de los archivos internos de WordPress.
Poder permitir el acceso a elementos específicos
La directiva Allow permite excepciones a las reglas de Disallow. Por ejemplo, si se desea permitir el acceso a un archivo específico dentro de un directorio bloqueado, se puede hacer de la siguiente manera:
Allow: /wp-admin/admin-ajax.php– Permite el acceso al archivo admin-ajax.php, que puede ser necesario para ciertos plugins.
Inclusión del Sitemap
Agregar la ubicación del Sitemap en el archivo robots.txt facilita a los motores de búsqueda la indexación de las diversas páginas y publicaciones del sitio. Esto ayuda a que los bots comprendan la estructura del sitio y encuentren el contenido de manera más eficiente.
Sitemap: http://tusitioweb.com/sitemap.xml– Especifica la ubicación del sitemap de la web.
Crawl-delay y su efectividad
El parámetro Crawl-delay indica a los bots cuánto tiempo deben esperar entre peticiones de rastreo. Aunque no todos los motores de búsqueda respetan este parámetro, puede ser útil para gestionar la carga del servidor en sitios muy grandes o con recursos limitados.
Crawl-delay: 10– Los bots deben esperar diez segundos entre cada solicitud de rastreo.

Cómo configurar robots.txt para WordPress
Personalizar el archivo robots.txt en WordPress es un paso esencial para optimizar la visibilidad del sitio en los motores de búsqueda. A continuación, se presentan las configuraciones específicas según el tipo de sitio y el uso de etiquetas relevantes.
Configuraciones según el tipo de sitio web
La personalización del archivo robots.txt puede variar significativamente dependiendo del tipo de sitio web. Es importante adaptar las reglas a las necesidades específicas del proyecto, ya que un enfoque erróneo podría afectar negativamente el posicionamiento SEO.
- Blogs personales: Para un blog, es recomendable permitir el acceso a las páginas de contenido y bloquear áreas no relevantes, como los archivos de administración y ciertas secciones internas.
- Tiendas en línea: En el caso de sitios de comercio electrónico, es fundamental desincentivar el rastreo de páginas de checkout y de cuenta de usuario, al tiempo que se permite el acceso a las páginas de productos y categorías.
- Sitios corporativos: Los sitios web corporativos suelen necesitar que se indexen las páginas de servicios y contacto, mientras que se pueden bloquear recursos que no aportan valor al SEO, como archivos temporales o de desarrollo.
Uso de etiquetas noindex y nofollow
Las etiquetas noindex y nofollow son herramientas complementarias muy efectivas que deben considerarse al personalizar el archivo robots.txt. Estas etiquetas permiten un control más granular sobre cómo los motores de búsqueda tratan el contenido del sitio.
- Etiqueta noindex: Se utiliza para indicar a los motores de búsqueda que no deben indexar una página específica. Esto es útil para contenido que no es relevante para el SEO o que no se desea que aparezca en los resultados de búsqueda, como páginas de agradecimiento o de política de privacidad.
- Etiqueta nofollow: Se aplica a enlaces que no se desean rastrear. Al usar esta etiqueta, se puede evitar que el PageRank de una página se transfiera a ciertos enlaces, protegiendo así la autoridad de las páginas importantes.
Aplicar estas etiquetas junto con el archivo robots.txt permite un enfoque más controlado sobre la indexabilidad del sitio y ayuda a gestionar el contenido que los motores de búsqueda deben o no deben considerar. La combinación de estas técnicas es fundamental para una estrategia SEO sólida.

Ejemplo de archivo robots.txt bien configurado
La configuración adecuada del archivo robots.txt es fundamental para optimizar el rastreo y el SEO de un sitio web. A continuación, se presentan ejemplos concretos que ilustran cómo personalizar este archivo para diferentes tipos de sitios.
Caso práctico para un blog
Para un blog, es importante permitir que los motores de búsqueda rastreen las publicaciones y las páginas relevantes, pero también es crucial bloquear las secciones que no aportan valor al SEO, como el área de administración. Un archivo robots.txt sencillo pero eficaz para un blog podría tener el siguiente aspecto:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/ Allow: /wp-admin/admin-ajax.php Sitemap: http://tublog.com/sitemap.xml
En este caso, se permite el acceso a admin-ajax.php, lo que es fundamental para la funcionalidad del sitio, mientras que se bloquean áreas que no son útiles para los motores de búsqueda. El sitemap se incluye para facilitar el rastreo del contenido importante.
Configuración para comercio electrónico
Los sitios de comercio electrónico requieren una estrategia más cuidadosa debido a la gran cantidad de páginas que generan, como productos, categorías y artículos. Un archivo robots.txt optimizado para un sitio de comercio electrónico podría parecerse a esto:
User-agent: * Disallow: /carrito/ Disallow: /mi-cuenta/ Disallow: /pedido/ Allow: /productos/ Sitemap: http://tusitioweb.com/sitemap.xml
Este ejemplo restrige el acceso a secciones sensibles como el carrito y la cuenta del usuario, que no deben ser indexadas por los motores de búsqueda. Sin embargo, se permite el rastreo de la sección de productos para asegurar que los clientes potenciales puedan encontrar las ofertas. Nuevamente, el sitemap es esencial para ayudar a los motores a descubrir el contenido valioso.
Herramientas para probar y solucionar problemas en el archivo robots.txt
Probar y solucionar problemas en el archivo robots.txt es imprescindible para asegurar que los motores de búsqueda interactúan correctamente con un sitio web. Hay herramientas específicas que permiten verificar el funcionamiento de este archivo y solucionar posibles errores que puedan surgir.
Uso del probador de robots de Google Search Console
Google Search Console ofrece un probador de robots que permite a los administradores web probar su archivo robots.txt y asegurar su correcta configuración. Esta herramienta es fundamental para identificar problemas de rastreo y optimizar la visibilidad del sitio.
Para utilizar el probador, se debe acceder a la sección correspondiente dentro de Google Search Console. Allí, se pueden realizar las siguientes acciones:
- Probar URLs: Introducir una URL específica para verificar si está permitida o bloqueada según las reglas del archivo robots.txt.
- Visualización del archivo: Revisar el contenido actual del archivo robots.txt y su estructura.
- Errores detectados: Identificar y corregir errores que podrían afectar el rastreo de las páginas.
El uso regular de esta herramienta permite mantener un archivo robots.txt optimizado y libre de problemas, fomentando una mejor indexación del contenido.
Resolución de errores comunes
Identificar y resolver errores en la configuración del archivo robots.txt es crucial para mejorar la efectividad del rastreo de los motores de búsqueda. Algunos de los errores más comunes incluyen:
- Rutas incorrectas: Asegurarse de que las rutas especificadas en las directrices Disallow o Allow sean correctas. Un error tipográfico puede causar que se bloqueen secciones del sitio que deberían ser accesibles.
- Reglas contradictorias: Es posible que se incluyan directrices que se contradicen entre sí, como un Disallow seguido de un Allow para el mismo directorio. Esto puede llevar a confusión y dificultades en el rastreo.
- Acceso a páginas clave: Bloquear por error el acceso a páginas importantes, como las que contienen contenido que se desea indexar, afectará negativamente al SEO del sitio.
- Formato incorrecto: Un archivo mal formado, con errores de sintaxis o mal uso de las directrices, puede provocar que los bots de búsqueda ignoren el archivo por completo.
Supervisar y ajustar el archivo robots.txt con herramientas como el probador de Google Search Console es fundamental para evitar estos errores. La implementación de correcciones precisas contribuirá a mejorar el posicionamiento y la interacción de los motores de búsqueda con el sitio web.

¿Necesitas ayuda con el SEO de tu negocio?
¡Marca la diferencia! Solicita más información sin compromiso
Errores comunes al configurar el archivo robots.txt
La configuración del archivo robots.txt puede parecer sencilla, pero existen varios errores que pueden afectar de manera significativa el rastreo y la indexación del sitio web. A continuación se describen algunos de los errores más comunes que se suelen cometer.
Mal uso de Disallow y Allow
Uno de los errores más habituales es el mal uso de las directrices Disallow y Allow. Estas instrucciones son fundamentales para controlar cómo los motores de búsqueda interactúan con el sitio. Un error común incluye:
- Especificar una regla
Disallowque bloquee por error directorios o archivos importantes, lo que puede impedir la indexación adecuada de contenido esencial. - No utilizar correctamente la directriz
Allowpara permitir el acceso a ciertos archivos dentro de directorios bloqueados, lo que limitaba el rastreo de funcionalidades necesarias. - Olvidar aplicar la sensibilidad de mayúsculas y minúsculas, ya que los nombres de archivos y directorios deben coincidir exactamente.
Estos errores pueden causar que contenido valioso no sea indexado, afectando el rendimiento SEO del sitio.
Configuraciones de bloqueo involuntario
Las configuraciones de bloqueo involuntario son otro desafío frecuente. Esto puede surgir de múltiples formas, incluyendo:
- Bloquear todo el sitio, utilizando un
Disallow: /, lo que evita que cualquier página sea rastreada. - Incluir reglas que impidan el acceso a archivos clave como hojas de estilo o scripts necesarios para la correcta visualización del sitio.
- Aplicar directrices que, si bien pueden tener la intención de limitar el acceso a contenido duplicado, terminan bloqueando secciones que son importantes para el SEO.
La revisión cuidadosa del archivo robots.txt y la realización de pruebas pueden prevenir estos contratiempos y asegurar que el sitio esté optimizado para su visibilidad en motores de búsqueda.
